Unique Info About How To Build Spark
How To Build Spark From Source And Deploy It A Kubernetes Cluster In 60 Minutes | By Nikolay Dimolarov Towards Data Science

Plug Wires: Build Them Right - Holley Motor Life

How To Build Spark Plug Wires | Hagerty Diy - Youtube

Quick Tech: How To Build Your Own Spark Plug Wires
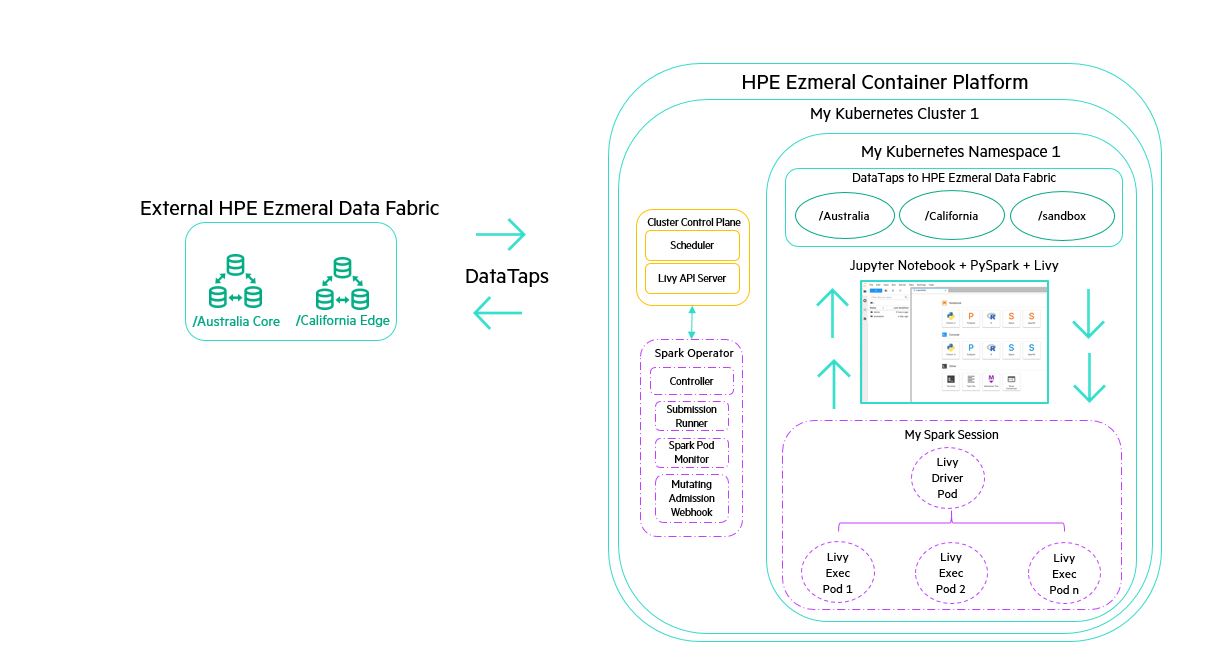
On-premise Adventures: How To Build An Apache Spark Lab On Kubernetes | Hpe Developer Portal

Building Spark Lineage For Data Lakes
Df = spark.read.csv('.csv') read multiple csv files into one dataframe by providing a list.
How to build spark. This means the time it will take is 950 spark hours / 1 spark = 950 hours (appx. For instance, you can build the spark streaming module using: For instance, you can build the spark streaming module using:
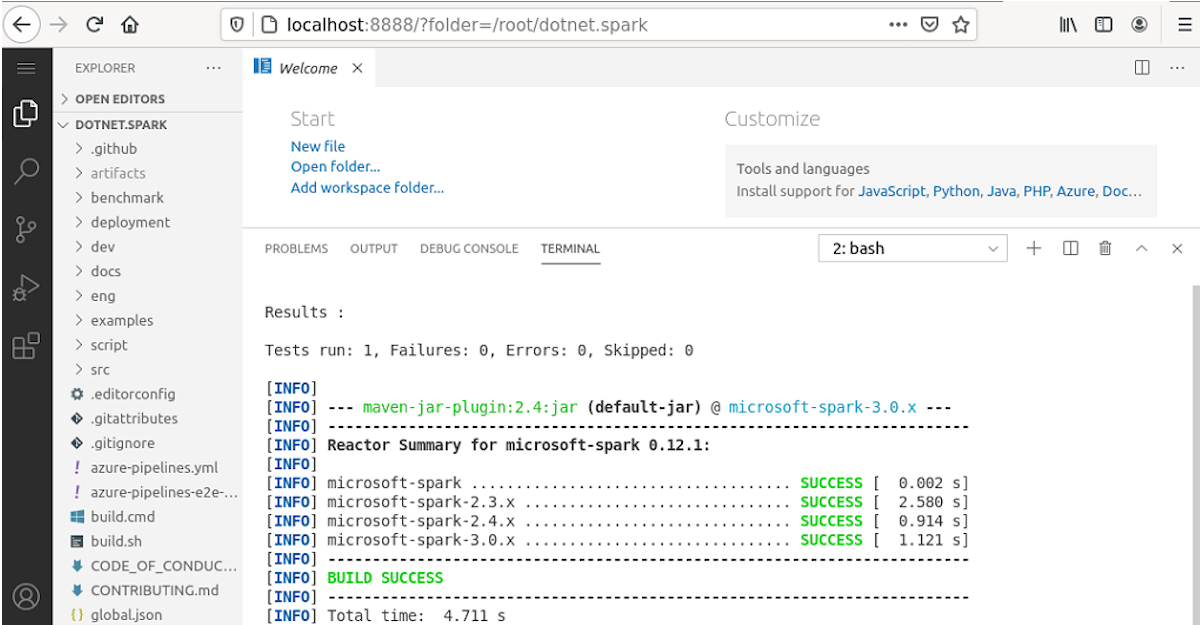
Building spark using maven requires maven 3.0.4 or newer and java 6+. Building spark with java 7 or later can create jar files that may not be readable with early versions of java 6,. How to build apache spark data pipeline?
Spark’s architecture on kubernetes from their documentation. This blog will show you how to use apache spark native scala udfs in pyspark, and gain a significant performance boost. Building a fat jar file.
Kubectl create serviceaccount spark kubectl create. Scala is the spark's native language, and hence we prefer to write spark. A data pipeline is a piece of software that collects data from various sources and organizes it so that it can be used strategically.
These steps will help in understanding the overall building process for any.net for spark application. Due to range and nature of spark, even content that outstrips. This build is an excellent league starter, and requires very little investment to start rolling over maps and bosses.
For example, machine learning (ml), extract. To a certain extent, everything in development may be represented as a data pipeline. Tl;dr we need to create a service account with kubectl for spark:

How To Build A Spark Gap Tesla Coil (sgtc) : 10 Steps (with Pictures) - Instructables

Quick Tech: How To Build Your Own Spark Plug Wires

How To Make Spark Plug Wires

Sumax 8mm Build-your-own Spark Plug Wires For Harley | 10% ($3.96) Off! - Revzilla

How To Build A Spark Gap Tesla Coil (sgtc) : 10 Steps (with Pictures) - Instructables

How To Build A Simple Spark Web Application | Engineering Education (enged) Program Section

Scala - How To Build Spark From The Sources Download Page? Stack Overflow
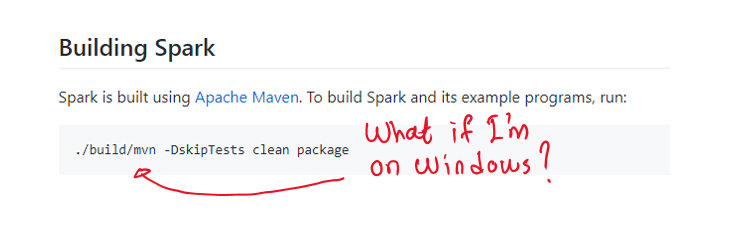
How To Build And Explore Apache Spark On Windows | By ___ Medium

Spark Building Construction - Wordpress Theme | Wordpress.org

Spark Class Build Fin - Youtube
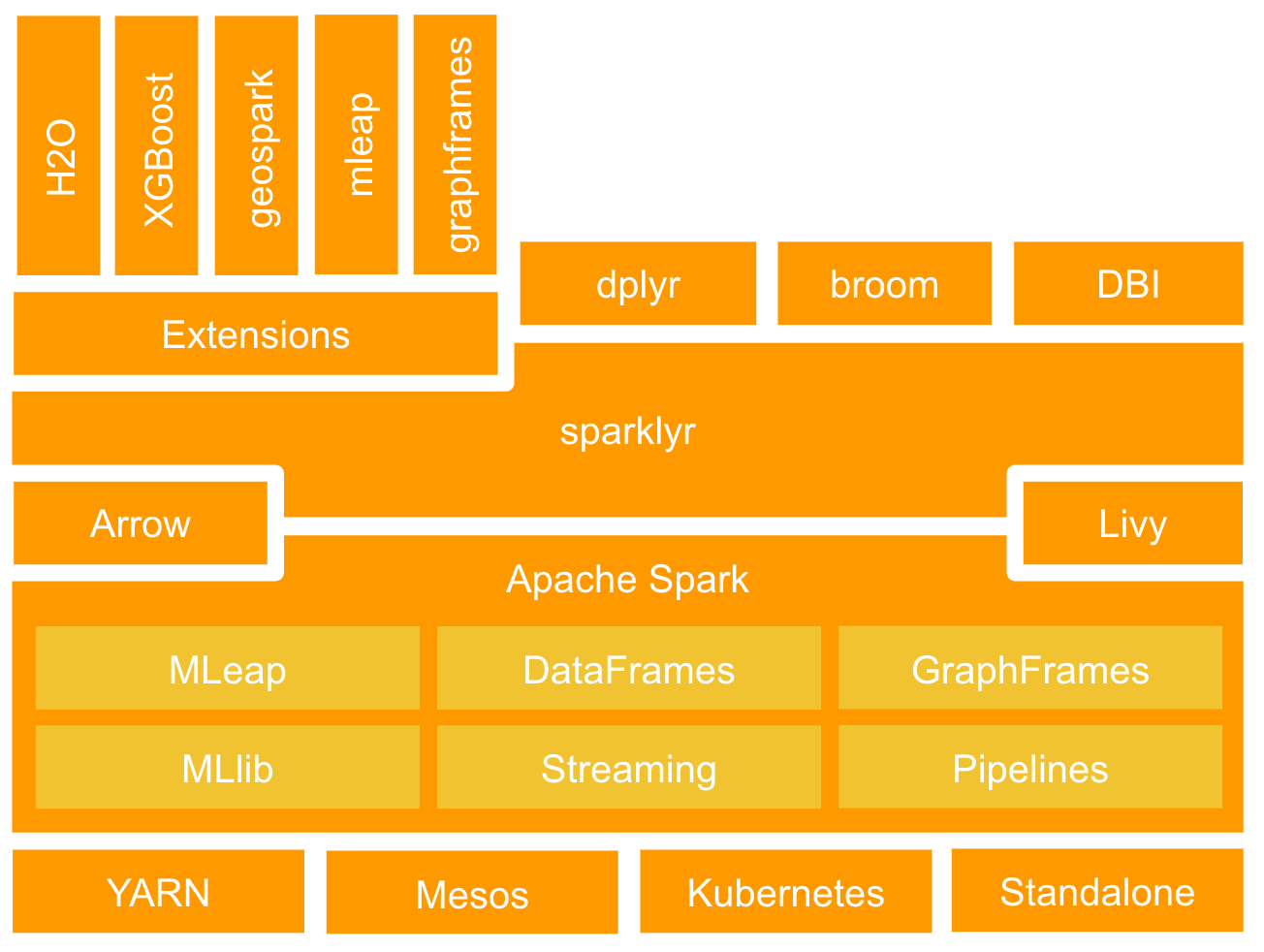
Run Your R (sparklyr) Workloads At Scale With Spark-on-kubernetes | By Jean Yves Towards Data Science

How To Build An Alpha Particle Spark Detector : 6 Steps - Instructables

Build Your Open Source Big Data Distribution With Hadoop, Hbase, Spark, Hive & Zeppelin | Adaltas